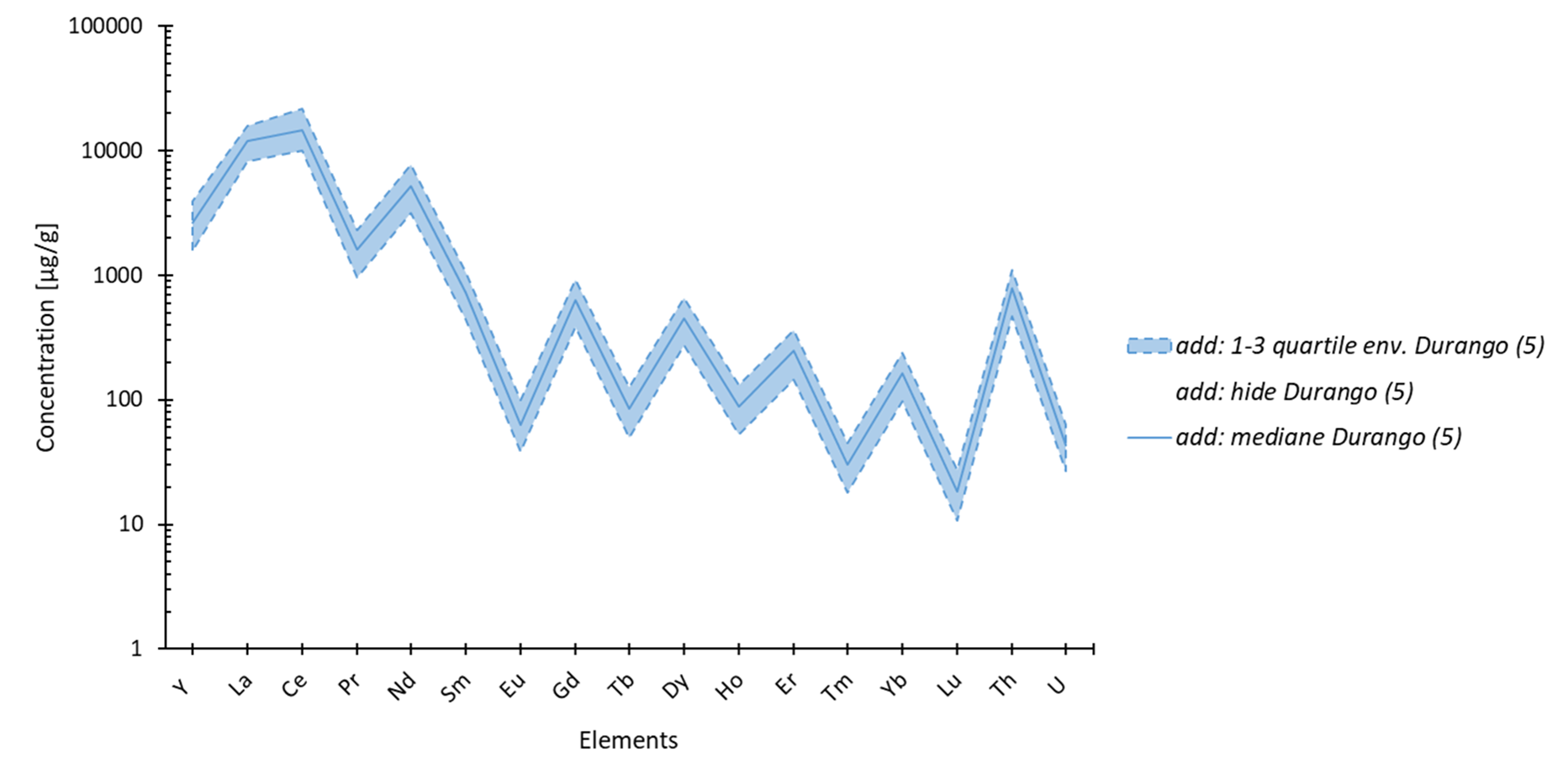
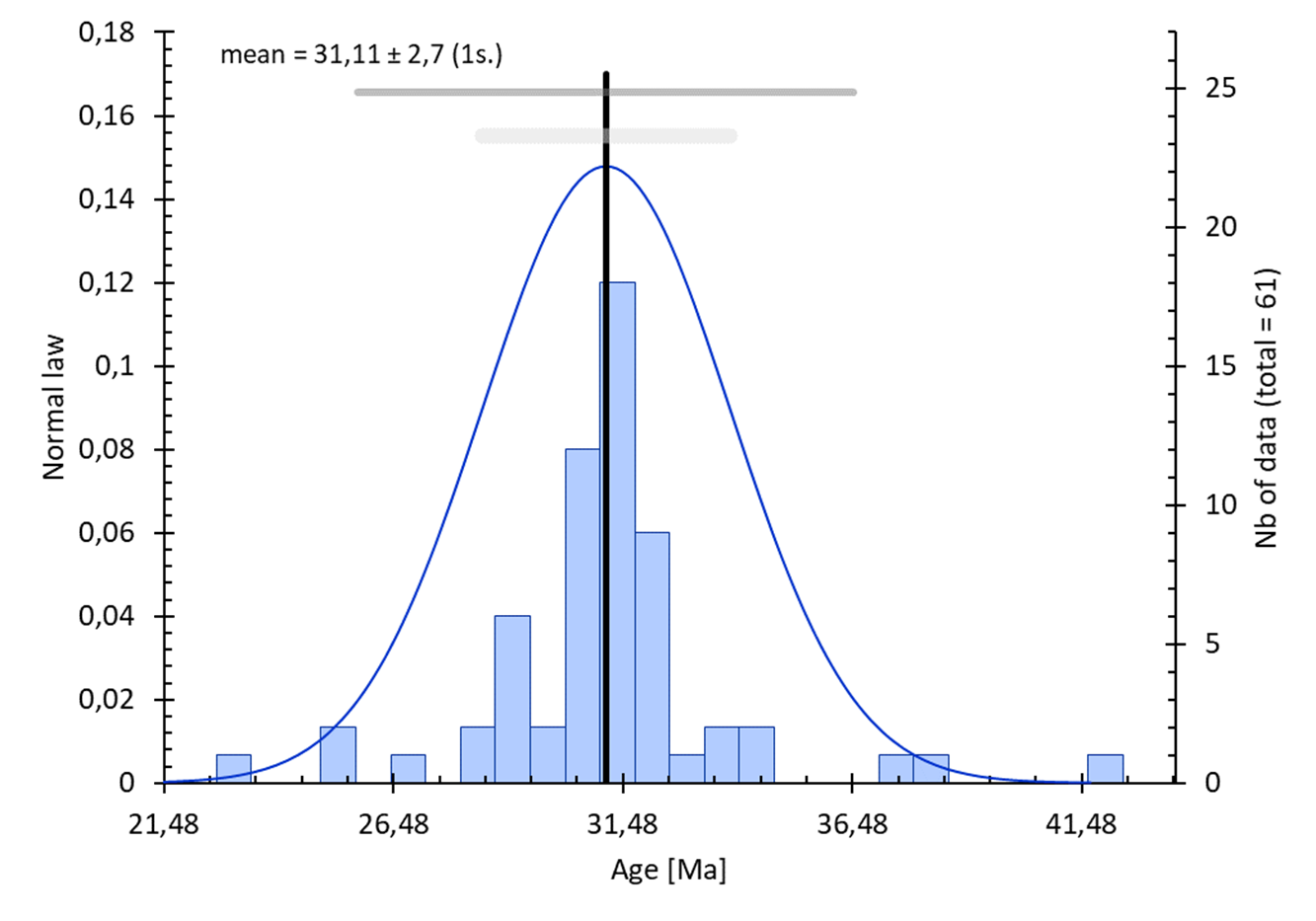
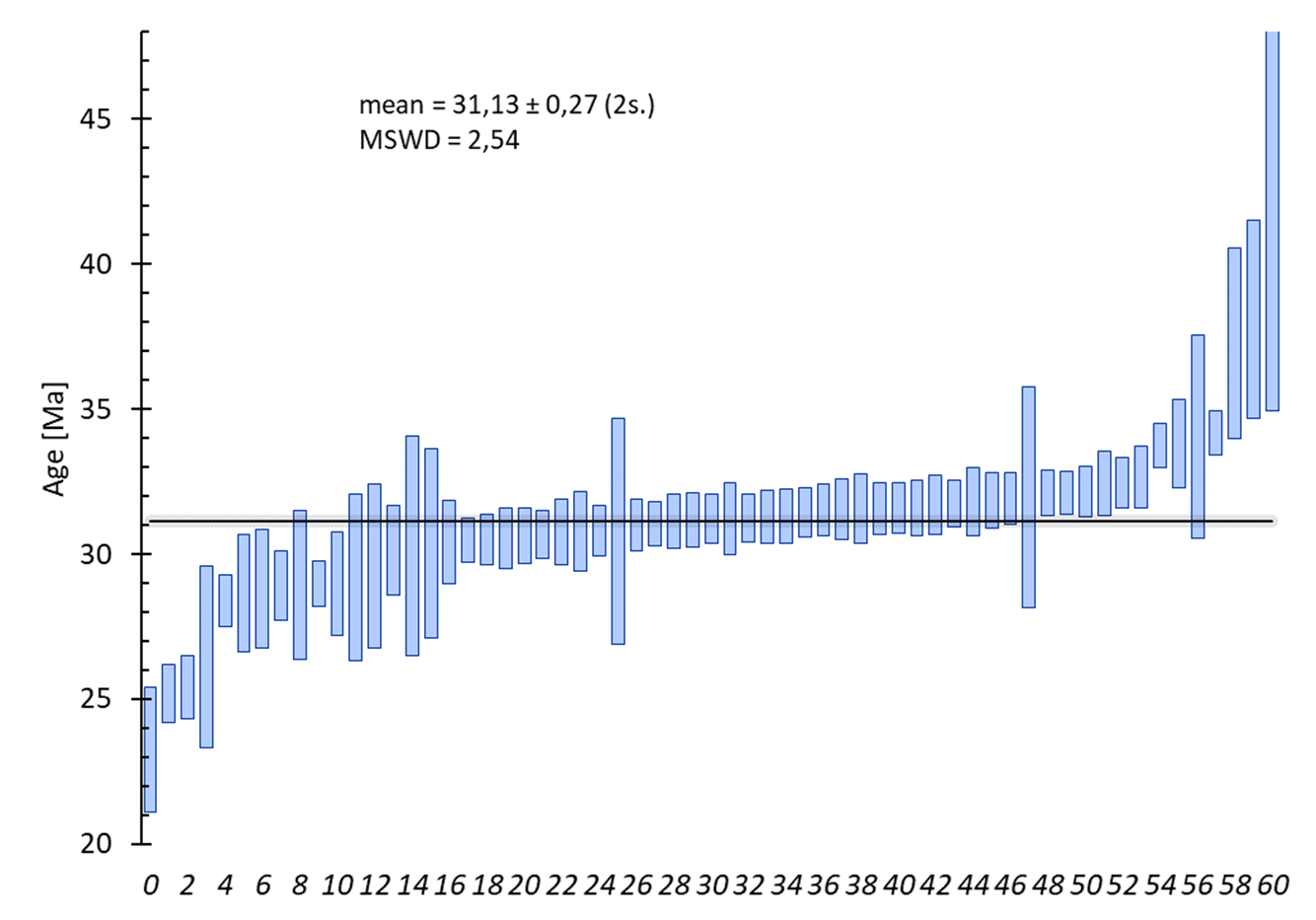
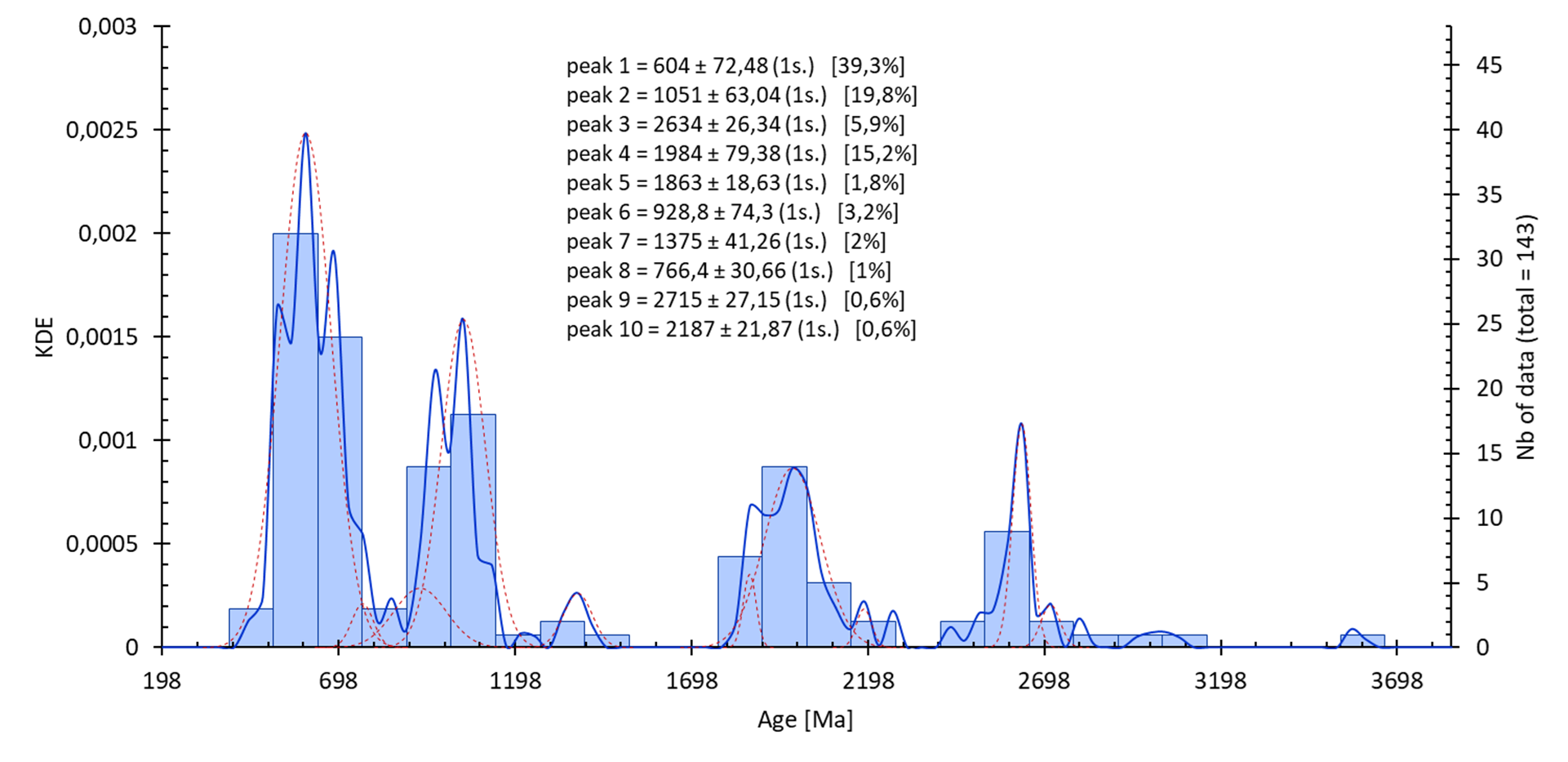
réalisables depuis un set de données sélectionné avec un exemple du résultat obtenu (voir le tuto sur la création de graphique statistique). À savoir que certain de ces graphiques s’accompagnent d’une fenêtre pour entrer les paramètres du traitement.
- calcul d’une distribution/loi normale
- calcul d’une moyenne pondéré
- calcul d’un KDE
- calcul/affichage de population
- affichage d’un radial/Galbraith plot
Entrer des données de traitement statistique :

« X axe name » : nom de l’axe des X (mémorisé par Better Plot)
« Histogram » : paramètres réglants la construction des histogrammes
- min : valeur basse de l’intervalle minimum
- max : valeur haute de l’intervalle maximum
- intervalle : gamme des intervalles de chaque bar de l’histogramme
« KDE » : paramètres réglants le calcul de la courbe KDE
- resolution : définit le nombre de points dans la courbe KDE pour une bar d’histogramme. Augmenter la résolution affine la courbe, mais prend plus de temps de calcul.
- bandwith ponderation : permet de moduler le taux d’aplanissement de la courbe KDE (de base égal à 1)
« Peak » : paramètres contrôlant la recherche de pic dans un KDE
- weighted sum research : effectue une pondération lors de la recherche de pic. Peut-être utile dans le cas de populations très proches.
- manually enter peak : permet d’entrer les populations soit même (déjà définit par l’intermédiaire d’autre logiciel, voir la section définit).
Distribution / loi normale :
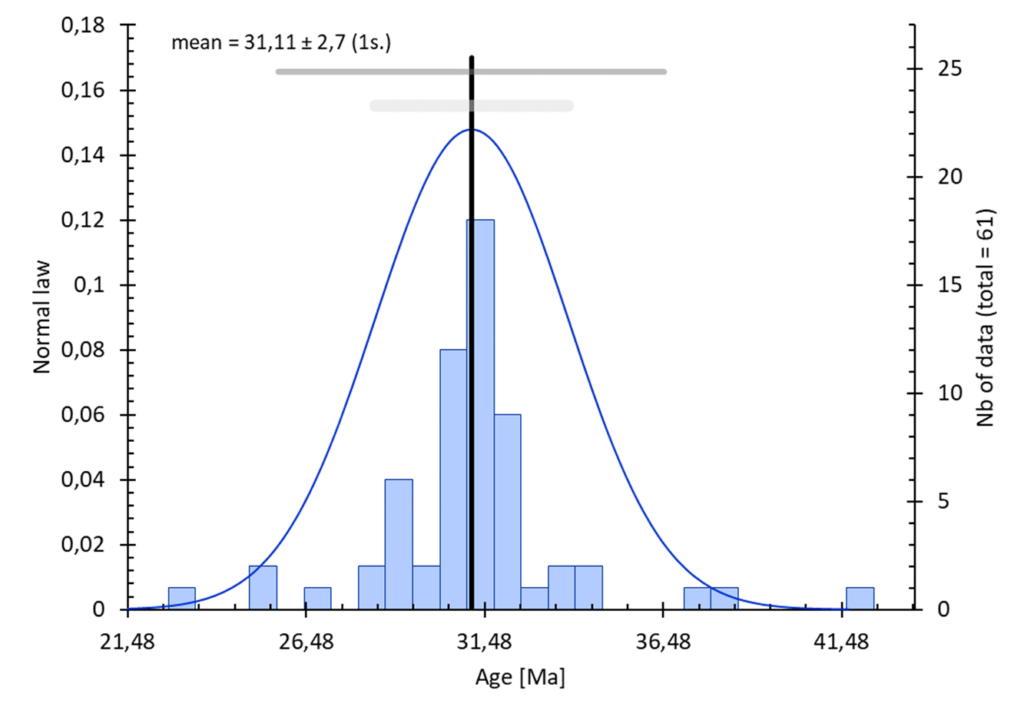
Options :
- sélection : 1ʳᵉ colonne = donnée, 2ᵉ colonnes (optionnel) = incertitude (1 sigma)
- incertitude : prise en compte des incertitudes sur le set de données si disponible
- intervalle : possibilité de sélectionner les paramètre de construction de l’histogramme. Voir l’aide sur l’entrée des données statistiques.
- calcul statistique :
blablablalblalblalbalb
Moyenne pondérée :
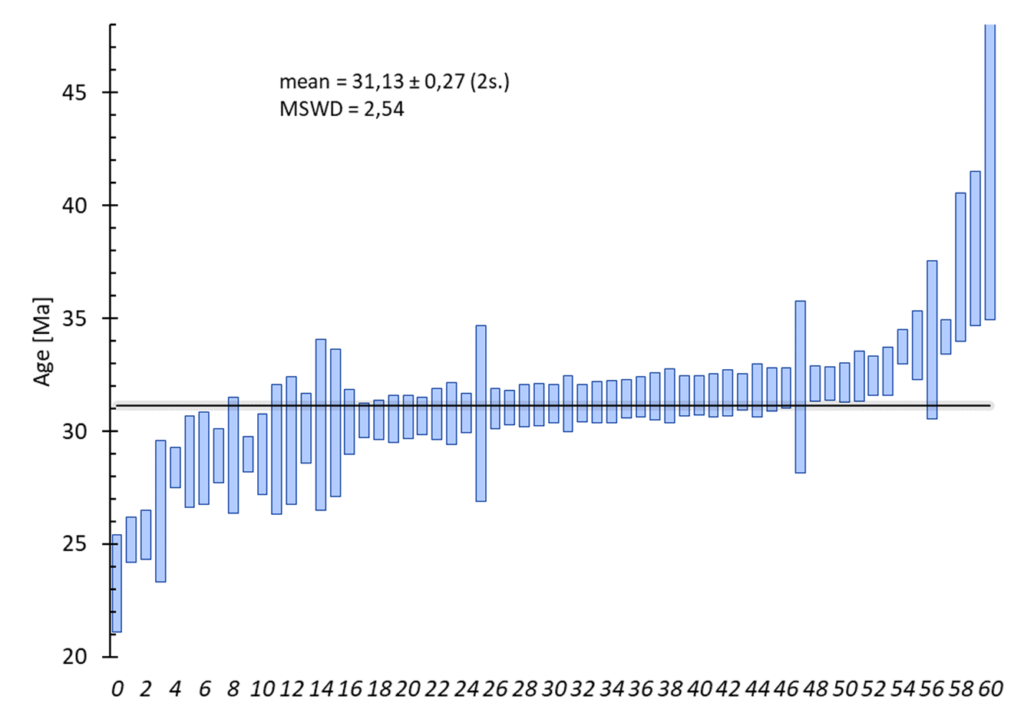
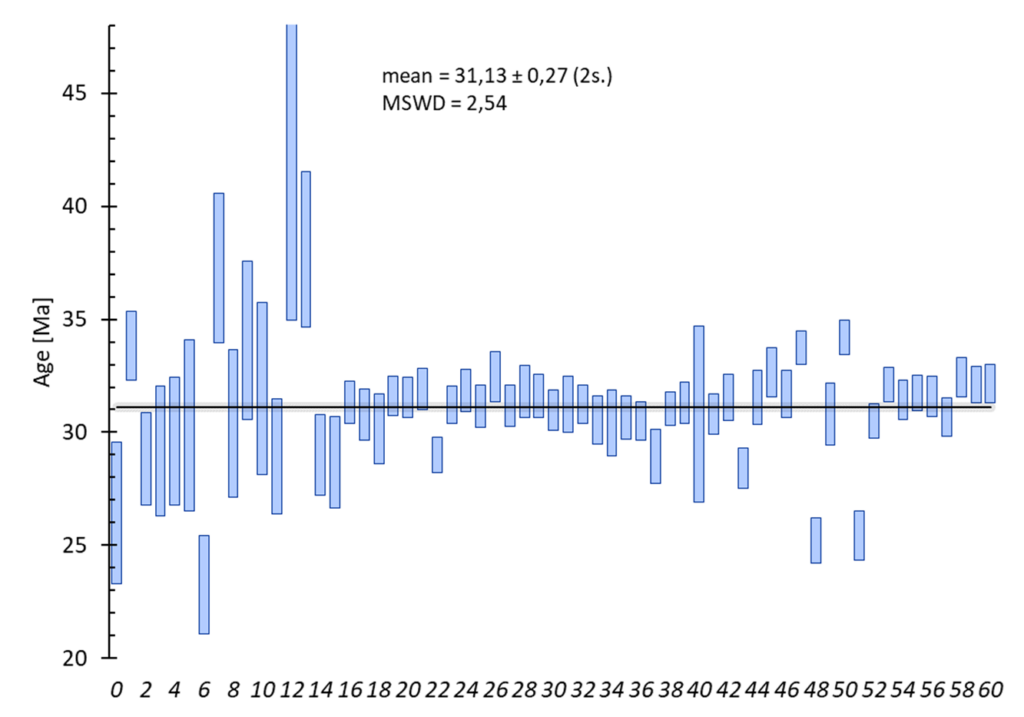
Options :
- sélection : 1ʳᵉ colonne = donnée, 2ᵉ colonnes = incertitude (1 sigma)
- classement des données : possibilité de classer les données par ordre croissant. Voir l’aide sur l’entrée des données statistiques.
- calcul statistique :
blablablalblalblalbalb
Calcul d’un KDE (estimation par noyau) :
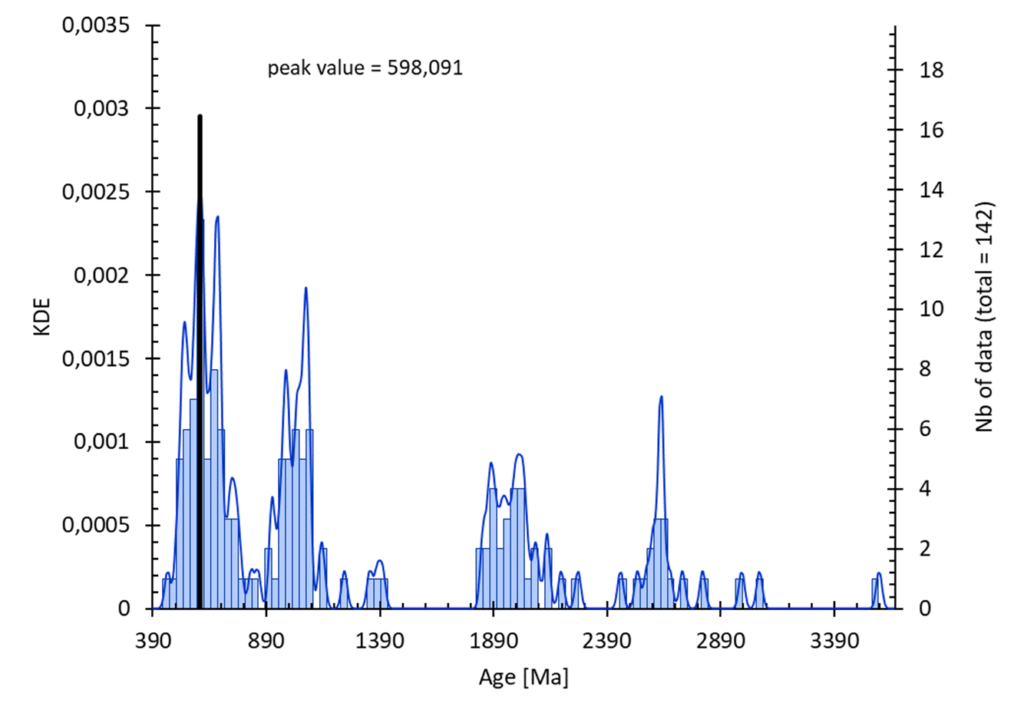
Options :
- sélection : 1ʳᵉ colonne = donnée, 2ᵉ colonnes (optionnel) = incertitude (1 sigma)
- incertitude : prise en compte des incertitudes sur le set de données si disponible
- intervalle : possibilité de sélectionner les paramètre de construction de l’histogramme. Voir l’aide sur l’entrée des données statistiques.
- calcul statistique :
Calcul ou représentation de populations :
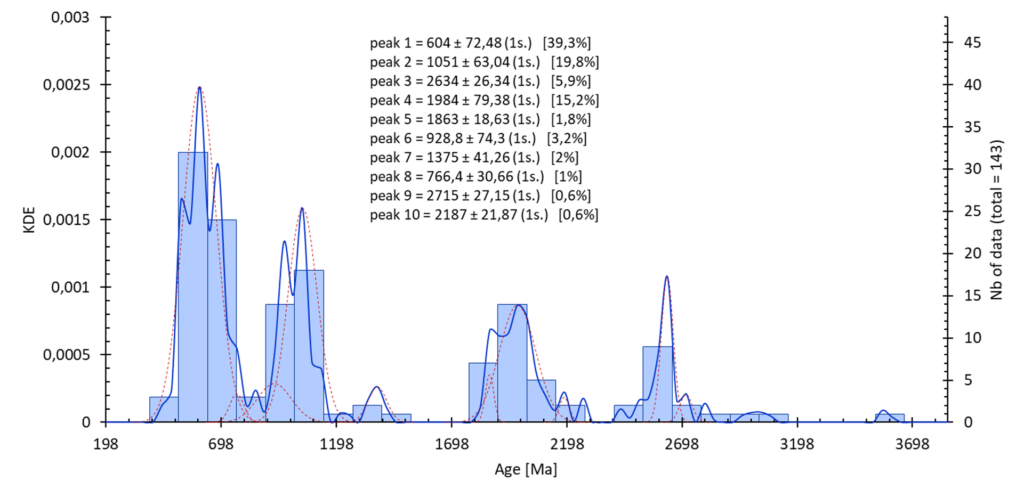
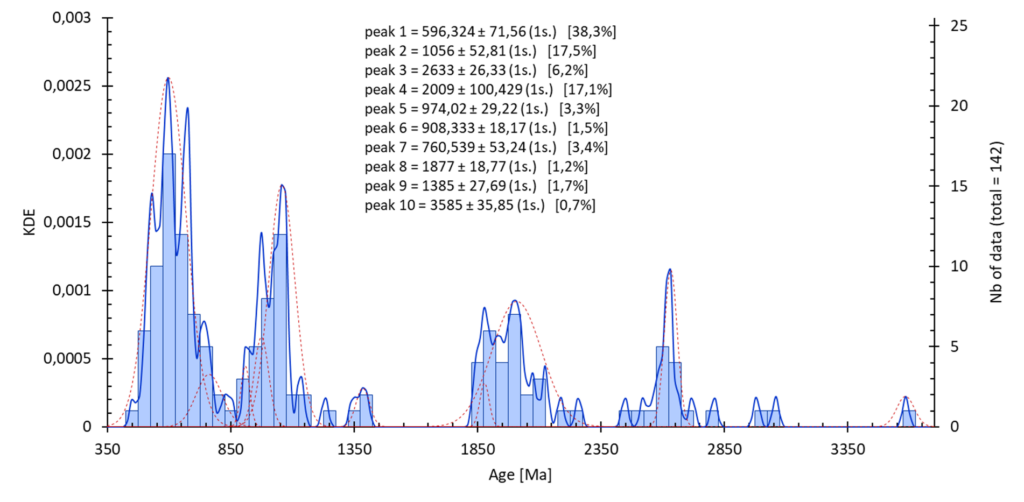
Options :
- sélection : 1ʳᵉ colonne = donnée, 2ᵉ colonnes (optionnel) = incertitude (1 sigma)
- incertitude : prise en compte des incertitudes sur le set de données si disponible
- intervalle : possibilité de sélectionner les paramètre de construction de l’histogramme. Voir l’aide sur l’entrée des données statistiques.
- population : possibilité d’entrée des données de population (moyen + 1 sigma) ou de les estimer depuis le set de donnée.
- calcul statistique :
Représentation d’un radial / Galbraith plot :
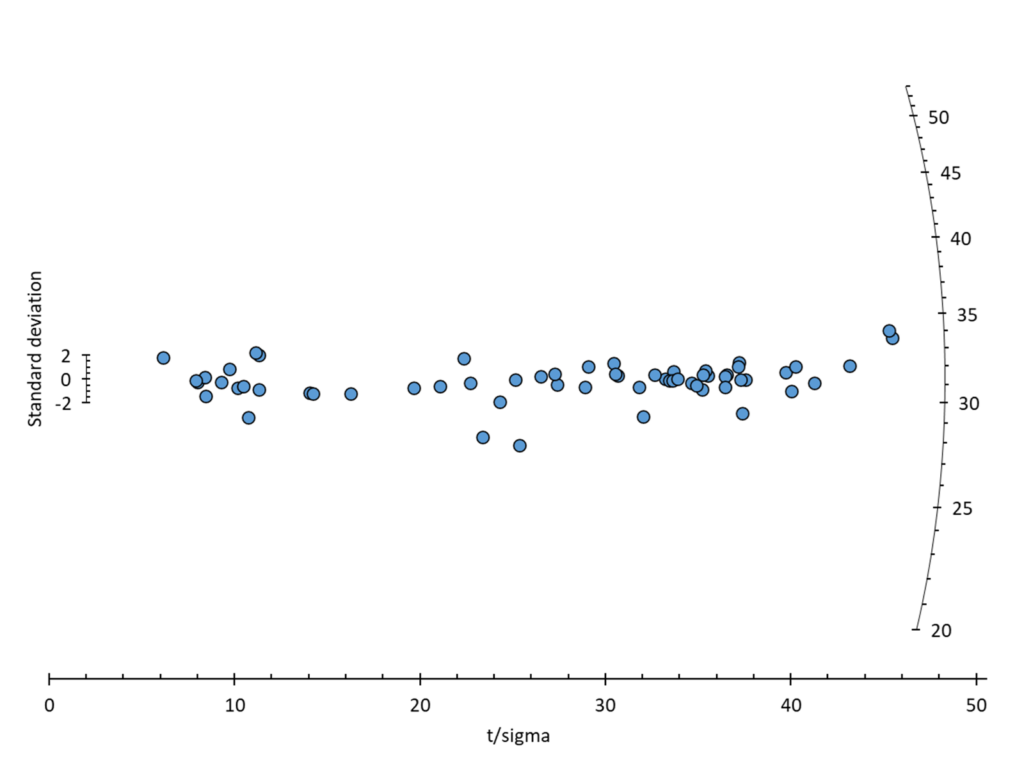
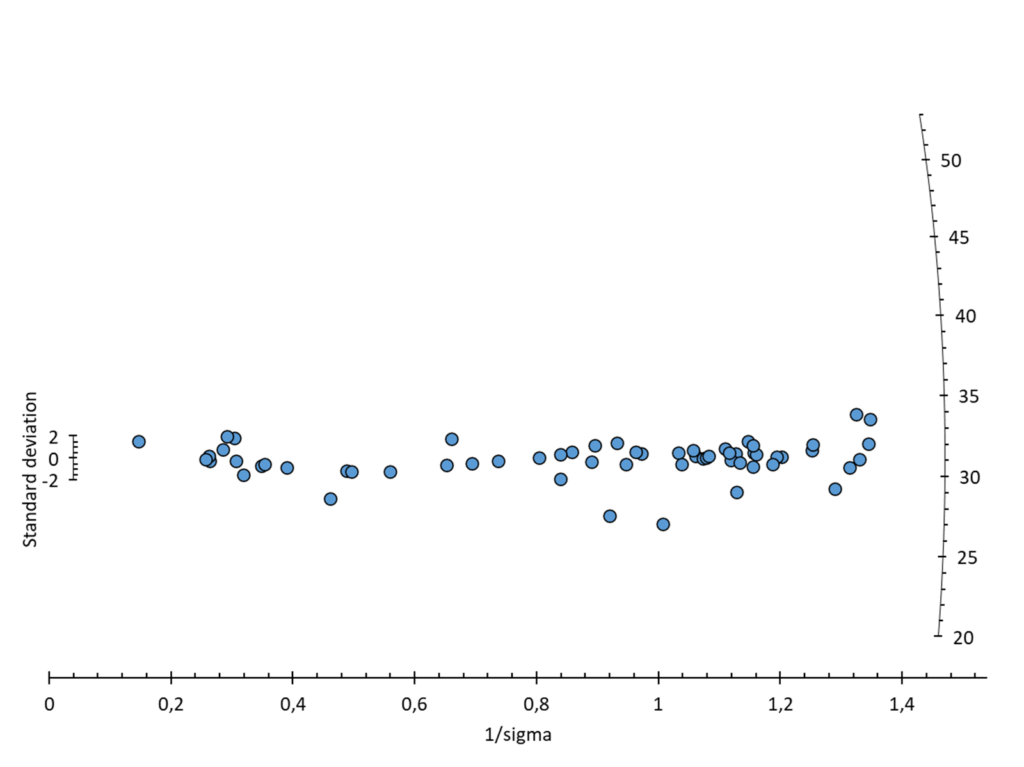

Options :
- sélection : 1ʳᵉ colonne = donnée, 2ᵉ colonnes = incertitude (1 sigma)
- projection : il est possible de sélectionner entre une projection linéaire ou logarithmique de l’axe radial
- calcul statistique :